Hadoop Partition And Secondary Sort
This article will describe an implementation and process of Hadoop partitioning and secondary sorting. First we need to briefly understand the workflow of Hadoop map-reduce task. In the previous article, we briefly explained the operation mechanism of Hadoop. The mapper task will read the file and process the data, after processing the mapper task will pass the result to the shuffle. shuffle will sort and partition all the map task results, and then will pass the partitioned and sorted data to the reducer, the key-value pairs with the same key will be passed to the same reducer.
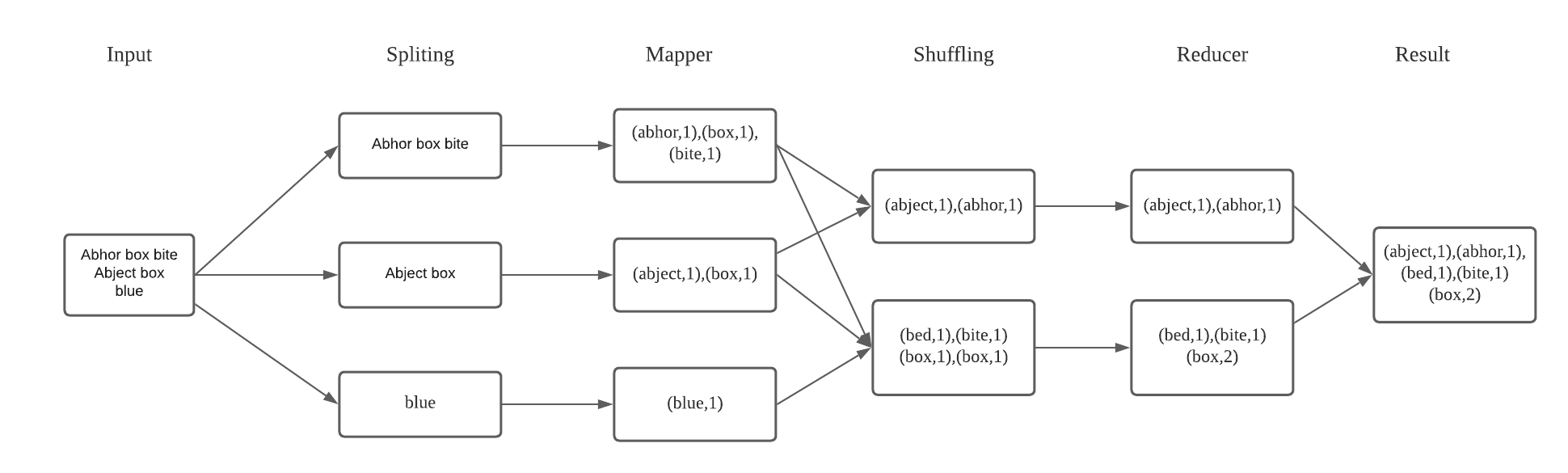
The default distribution method used by hadoop is based on the hash value, but in practice, this is not very efficient or performs the task as we require. For example, after partitioning, one node’s reducer is assigned 20 records while the other is assigned 10 million records, so imagine how inefficient this is. Or, we want to process the output file according to a certain rule, assuming there are two reducers, we want the final result to store the results of records starting with “a” in part-00000, and other results in part-00001, the default partitioner is unable to do. So we need to customize our own partition to choose the reducer of records according to our own requirements.
Why partition
We want to use Hadoop to get a ordered file by using a partition (because it will be sorted before partitioning). However if the input is huge (e.g. 10 GB), the performance of reducer is pretty inefficient which completely losing the advantage of the parallel architecture provided by MapReduce. We can use a partitioner to sort the data, so that when the reducer processes the data, it can be guaranteed that the data is already sorted. One partition corresponds to one reducer, so all the output of the reducer is ordered, we just need to merge all the output files, then the total file must be ordered.
Hadoop Streaming Partition
1 | mapred streaming \ |
1 | -D map.output.key.field.separator=, means the separator for the key is “,” |
For example, the input files is like this, name (input.txt)
1 | muse,curious,1 |
Put this file into hdfs:
1 | hdfs dfs -put input.txt input |
We partition by two different ranges of keys (mapreduce.partition.keypartitioner.options) (e.g.: key is (muse, curious) value is 1), and we get two different results.
The first command is partition based the first filed in the key.
1 | hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar \ |
The first reducer gets:
1 | cat,invent 2 |
The second reducer gets:
1 | muse,* 10 |
The last reducer is empty. With the result of the reducer we get the desired partition.
The first command is partition based the second filed in the key.
1 | hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar \ |
Reducer 1:
1 | cat,subject 5 |
Reducer 2:
1 | cat,invent 2 |
Reducer 3:
1 | muse,growing 4 |
Comparing the two output results we can see that different partition ranges lead to completely different partition results.
MRJob example
By using the given text file, I did a example that in mrjob.
1 | from mrjob.job import MRJob |
Run the code:
1 | python3 example.py -r hadoop hdfs:///user/xx/example.txt -o hdfs:///user/xx/output |
The result of three reducers:
None
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16muse,* 10
muse,age 12
muse,curious 1
muse,days 2
muse,do 3
muse,growing 4
muse,grown 5
muse,in 1
muse,more 3
muse,please 4
muse,these 3
muse,this 2
muse,times 5
muse,to 6
muse,with 9
muse,worth 01
2
3
4cat,invent 2
cat,subject 5
cat,ten 2
cat,want 8