HDFS的原理以及Hadoop的安装,MapReduce的运行流程,shuffle的运行机制。
hdfs 功能
HDFS:分布式文件管理系统
Hadoop fs:使用面最广,可以操作任何文件系统。
hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后者。
Hadoop/hdfs fs/dfs {args} {args}
hdfs 实现原理
当在使用hdfs dfs -put命令的时候,文件会被切块(文件块的大小通过参数来决定,默认是128M)存放到不同的datanode server里面,具体分布到哪个datanode取决于namenode server。
namenode会记录并维护不同的文件块所存放的具体位置(存放在哪个datanode里面),这些信息被称作元数据。
e.g.:
file被分割成3块,分别存放在datanode0, datanode1 and datanode 2。
那么在namenode会记录: file: {block0: datanode0-server, block1: datanode1-server, block2: datanode2-server。 当在使用hdfs dfs -get 的时候,系统会在namenode获取源数据,然后根据元数据记录的文件块存放的位置进行获取文件块,然后合并。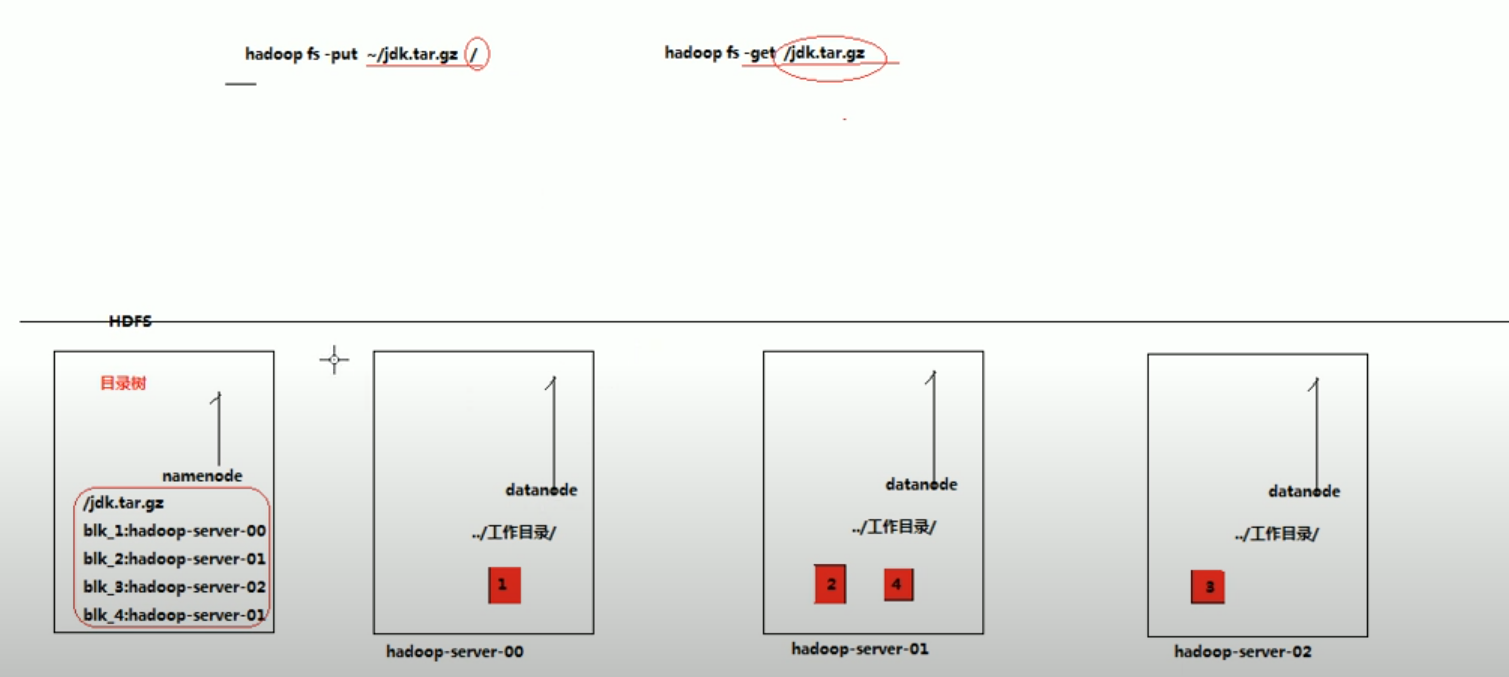
hdfs副本
为了防止datanode出现宕机情况,hdfs会对文件进行储存副本,副本的具体数量由用户设定。就是把同一文件块储存在不同的datanode上面。
hdfs特点
hdfs是适应一次写入,多次读的场景,不支持文件的修改。所以hdfs不适合做网盘应用,因为延迟高,开销大。
优点:可以线性扩展(不够存我直接再租几个服务器就够了),数据储存可靠性高,分布式运算处理方便。
hdfs 读/写数据流程
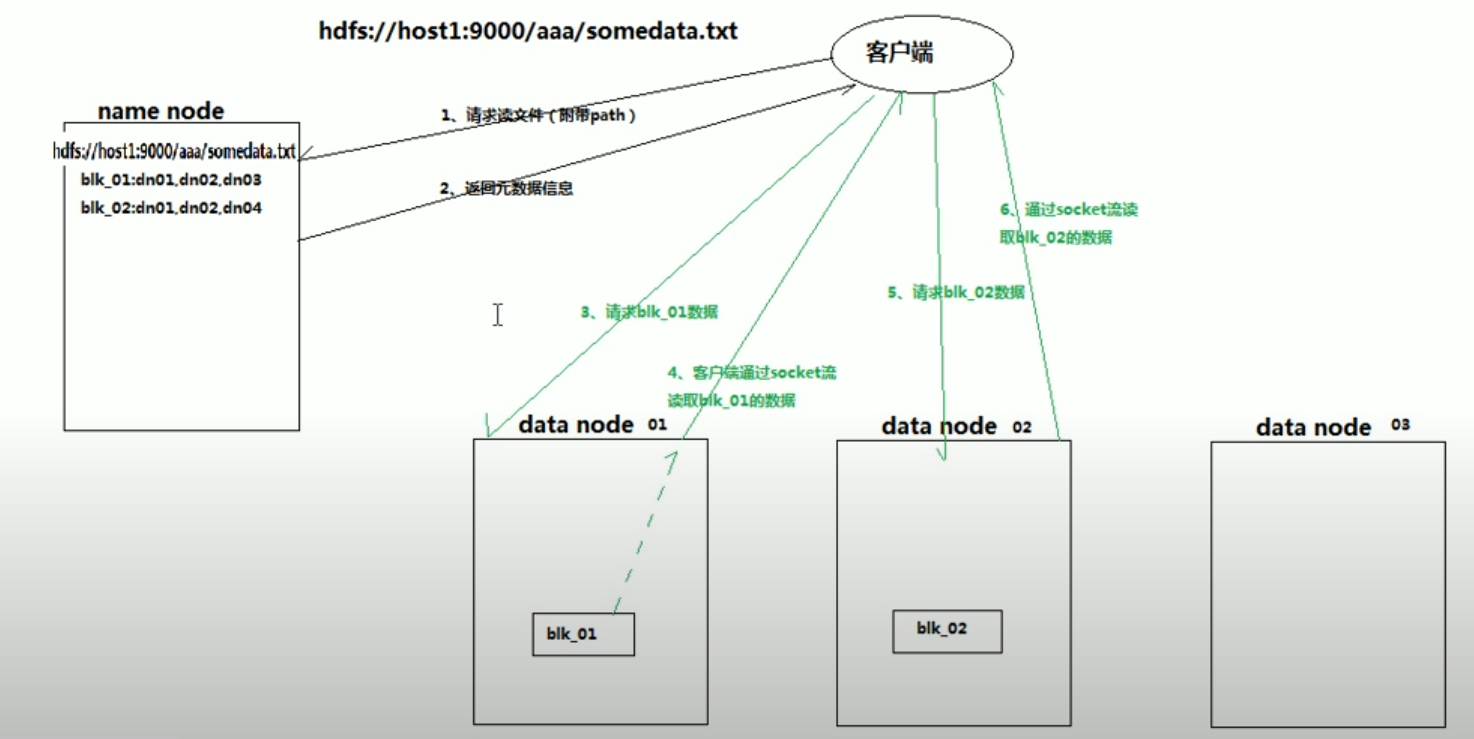
hdfs读数据流程
和namenode通信查询元数据,根据元数据找到文件快所在的datanode server
挑选一个datanode server(就近原则,然后随机),建立socket 通信
datanode开始发送数据(采用streaming),以packet为单位做校验
client以packet为单位接受,在本地缓存,然后写入目标文件(获取所有的文件快后进行合并)
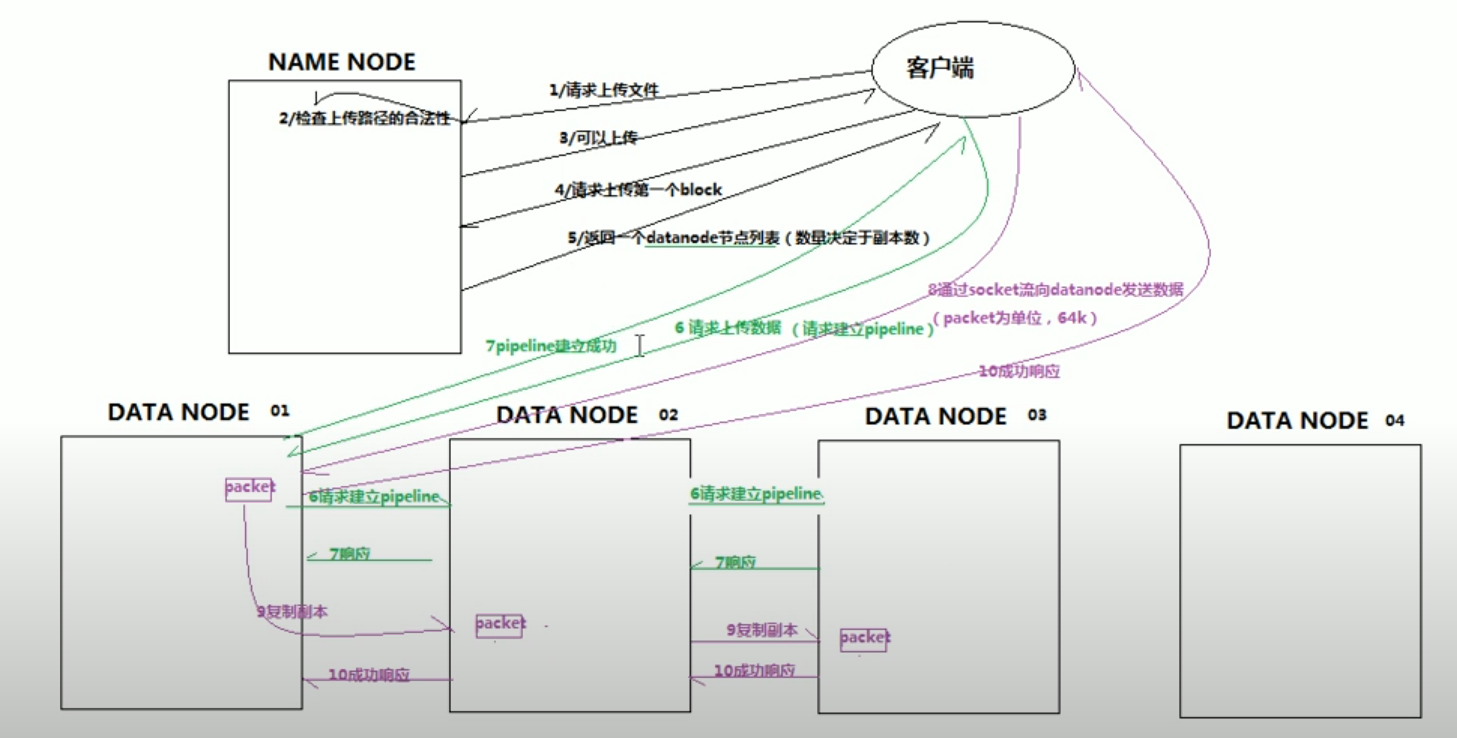
hdfs写数据流程
client和namenode通信并请求上传文件,namenode检查文件是否存在
namenode返回给client是否可以上传
client请求第一个block该传输到哪些datanode(因为包含副本)
namenode返回所需要上传的datanode server(数量取决于副本的数量),假设返回A B C三台server
client和datanode A建立pipeline(本质是RPC调用),A收到请求后调用B建立pipeline,B收到请求后和C建立pipeline,然后逐级返回client
client开始给A上传文件块,以packet为单位,A收到之后传给B,B收到之后传给C
当一个文件块上传完成之后,client再次请求namenode上传下一个文件块
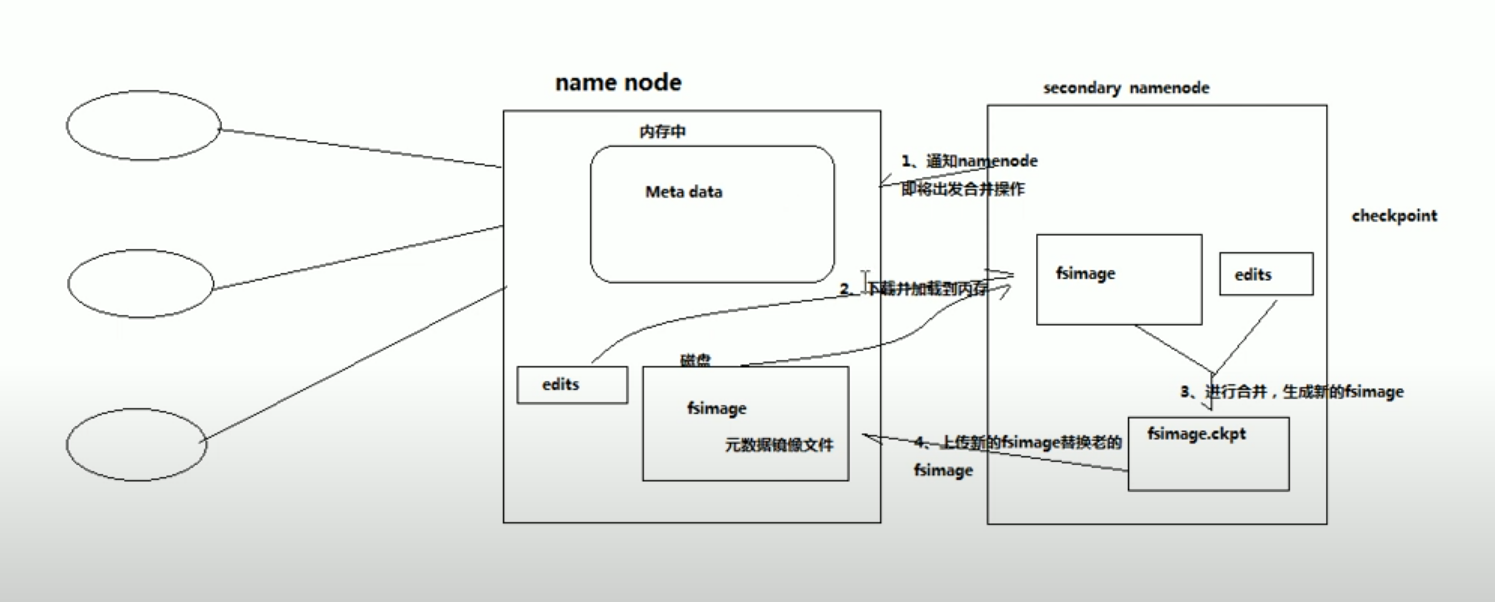
hdfs namenode 工作原理
namenode负责:响应client请求,维护路径树,管理元数据(查询,修改)
hdfs元数据管理机制
内存中有一份完整的元数据(特定的数据结构)
磁盘中有一个准完整的元数据的镜像文件
当client对hdfs中的文件新增或者修改的时候,首先会在edits文件中记录操作日志,当client操作成功之后,相应的元数据会更新到内存中。每隔一段时间会有secondary namenode将namenode上积累的所有edits和一个最新的元数据镜像下载到本地,并加载到内存中进行合并(这个过程被称为checkpoint)
MapReduce 原理
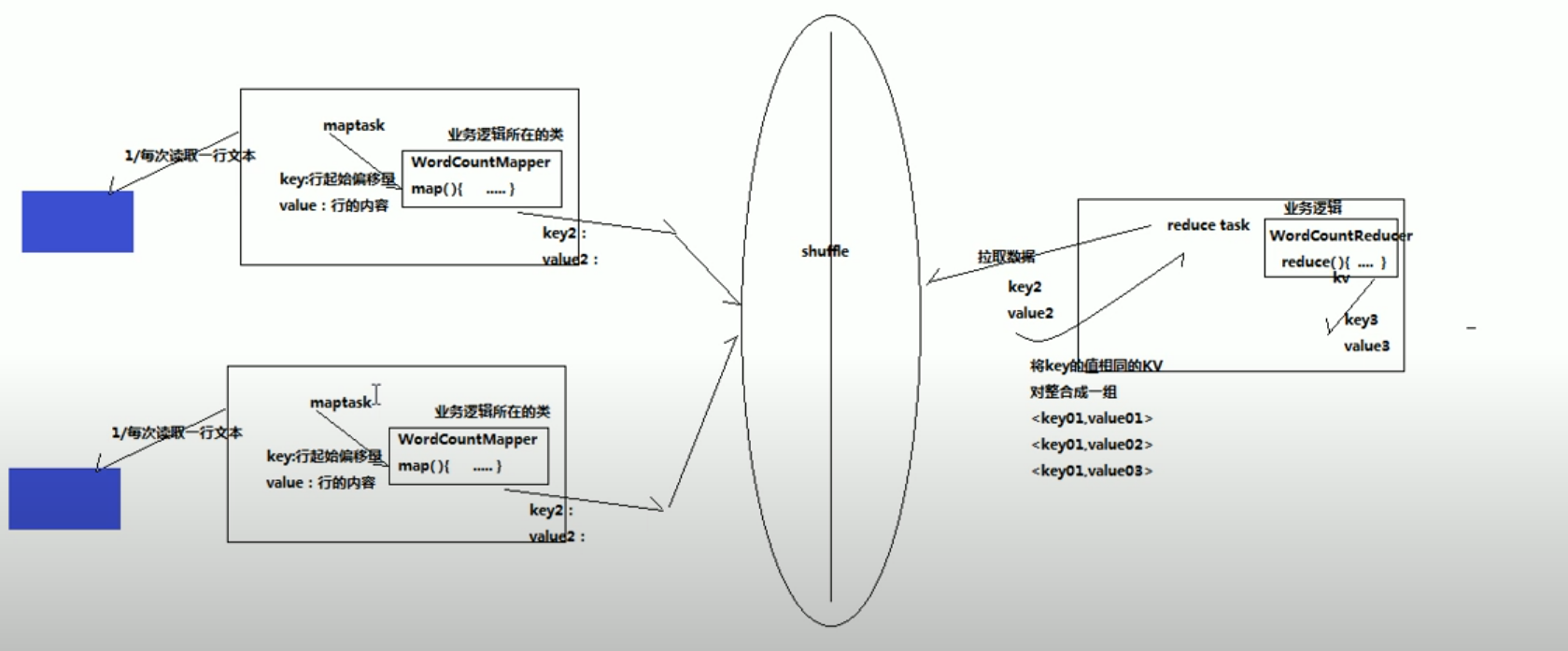
在map的时候会对同一个文件进行处理,每一个mserver里面的map会访问不同的部分,然后对文本数据进行处理,且map过程输出的格式是key value的形式。
在map task执行完之后会把数据传到shuffle里面,然后shuffle传递给reduce task。reduce会拉取在map里面处理过的数据,对key value进行整合(类似db里面的group by操作)。
shuffle原理
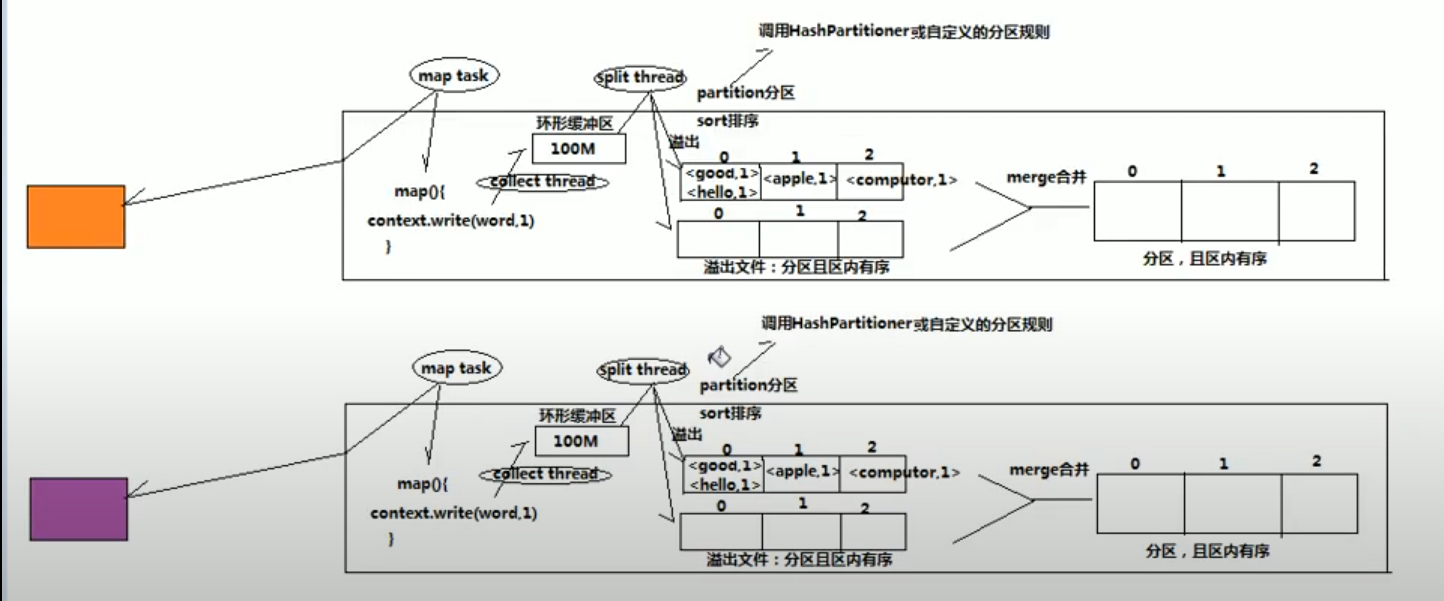
shuffle是map和reduce中间的数据调度机制,主要包含缓存,分区,排序
在map task里面有一个缓冲区,把处理过的key-value数据放到缓存里面,但是由于缓存有限,所以当缓冲区使用达到一定限制后(80%),split thread(一个线程,归map task管)会把缓冲区的数据写入到磁盘,split在处理缓冲数据的时候会对数据进行排序和分区,默认是hash partition进行分区,根据key的值hash分区。每split一次会写入到磁盘的一个新的文件(sort and partition)。在map完所有的数据之后,对所有溢出文件进行合并和排序,在合并的时候对每个分区的数据进行合并。
在reduce阶段,拉取所有map tasks的最终结果,并对这些数据做排序。
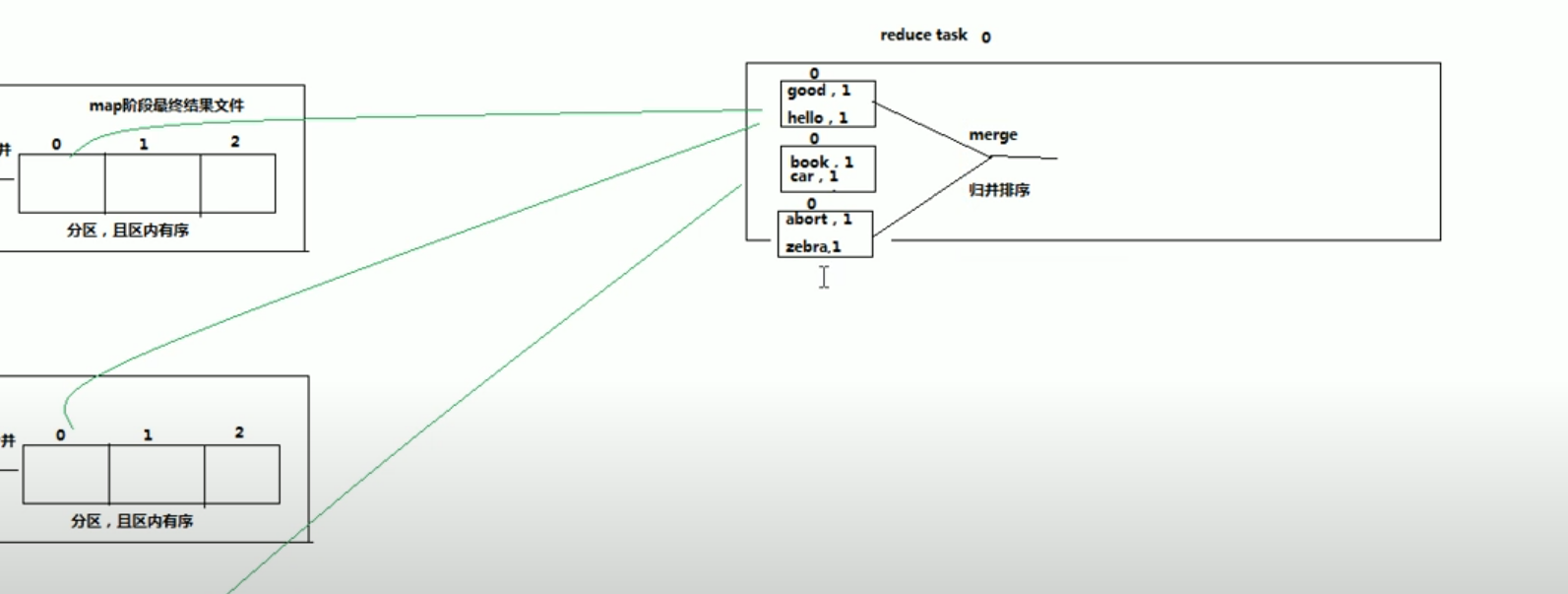
Reduce function会拿到根据key聚合数据,每个聚合组调用一次reduce方法。会有多个reduce task同时运行。